Inotify Usage Overview
How inotify rename cookies are managed.
inotify provides notification of renames (e.g. moves) via a pair of events, the IN_MOVED_FROM and IN_MOVED_TO events. In order to match these events into a pair each event contains an identifier unique to the pair called a "cookie". Move events only occur when watching the directory containing the moved item. Thus it possible to receive just one move event instead of a pair. So how do we match up move events? In the current kernel inotify implementation move events are always emitted as contiguous pairs with IN_MOVED_FROM immediately followed by IN_MOVED_TO. One could match move pairs by checking if the next event following a IN_MOVED_FROM was a IN_MOVED_TO, if so that constutes a pair, otherwise assume the matching move event will never be seen. This is how inotifytools works, it never looks at the cookie to perform the match nor tracks cookies, however it's depending on kernel behavior that is not guaranteed. The gamin file monitor keeps cookies in a hash table for subsequent lookup. However the downside of this is because the matching cookie may never arrive one has to periodically flush the table of old cookies based on a timestamp. This is a lot of extra logic and machine cyles even though it's probably the "correct" solution, especially considering it's reasonable to expect the matching cookie to be deliveried as the next event.We take a compromise approach that allows non-sequential delivery of cookies but requires little processing logic for the expected sequential delivery case and minimal overhead otherwise. We keep a small ordered cache of cookies in an array. The oldest cookie is the first array element, the youngest cookie is the topmost element. Because we know cookie operations always occur as either a single event or a pair of events the cache operator functions in a binary dual mode. We present a cookie to the cache, if it's not already in the cache we enter it in the cache discarding the oldest cookie if the cache is full. If the cookie was found we have a matching pair and the cookie is removed from the cache. The cache operator returns a boolean if the cookie was found thus indicating we have a complete pair (removing the cookie from the cache in the process, otherwise the cookie is entered in the cache).
When we flush an entry from the cache due to its age we provide a callback so that the user of the cache can be aware a matching cookie will never found for the rename. This knowledge may be important in some scenarios.
When a cache entry is removed it does require moving all the array elements above the removed entry down one position in the array. Moving the entire contents of an array is often though of as inefficient, but that is not always the case. Because the array is small and because only simple pointer arithmetic is used and because the memory moved has locality of reference (probably fitting in a cache line) the operation is much more efficient than removing an entry from a hash table or linked list (both of which probably also would include malloc/free). Lookups are also much more efficient for the same reason (simple array indexing in a small area of memory). But the biggest benefit comes from the fact in the common case of sequential paired events the cache size never grows beyond 1 and array elements are never shifted. It reasonable to keep the cache size small given we expect the matching cookie to arrive as the next event or shortly thereafter. We do not expect there to be many intervening move events, thus a cache size on the order of 4 to 8 entries is probably more than sufficient and keeps the processor cycles needed to manage the cache at a minimum. This seems like a good compromise between robustness and efficiency.
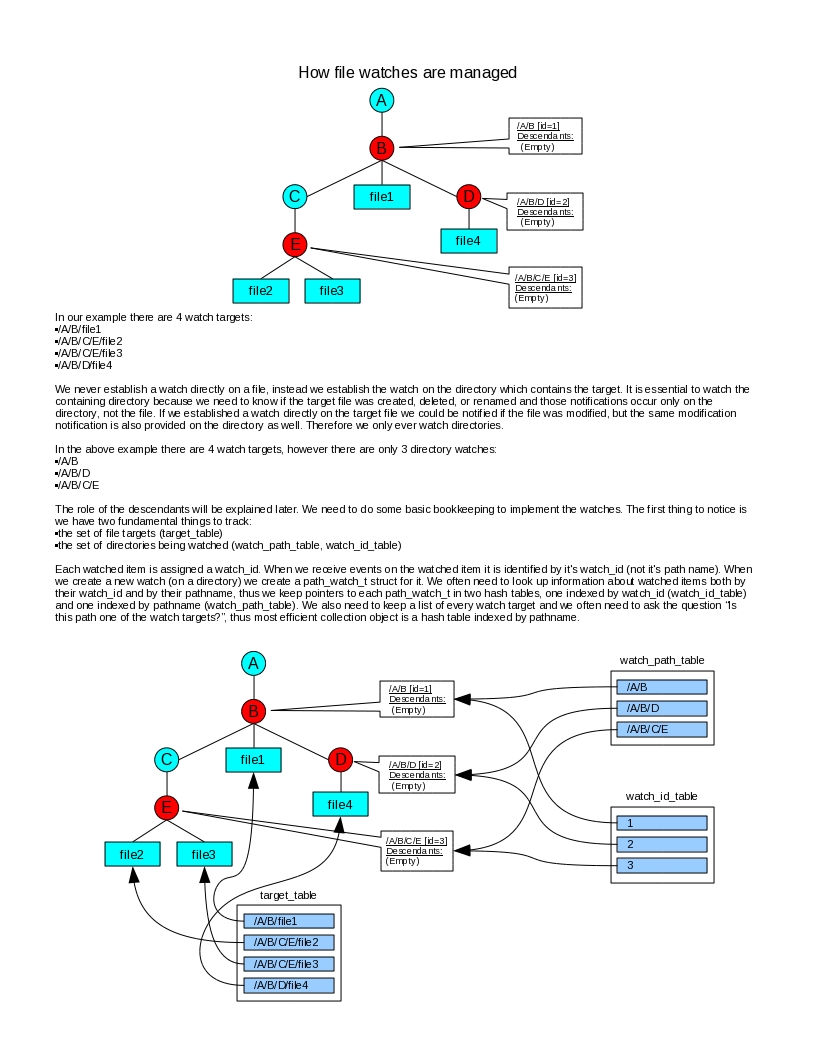
How Watch Points Watch Descendants
Inotify can watch either directories and files. One might expect since we're in the business of watching files we would elect to establish a watch on a file. However Inotify can only send an event when a file is created, deleted, or renamed when you are watching the directory containing the file, not the file itself. This is because file existence is really a change in directory contents. If you're using Inotify to watch a directory you also will be informed of modifications to any file in the directory, the same information that would be conveyed if you were watching an individual file. Thus it really only makes sense with Inotify to watch directories and not files.Inotify can only establish a watch on file system objects which exist. It is not possible to establish a watch on something which does not exist. The best one can do is watch on an existing directory where you expect either a file or a sub-directory to be created. Since you're watching an existing directory you'll be notified whenever that directory has a file or directory created in it or deleted from it.
Whenever we're asked to watch a file what we really do is set a watch on the directory which contains that file. Whenever the directory informs us that something has been added, removed, or modified in the directory we ask "Is that item something we're watching?" Thus every directory we establish a watch on has a data structure associated with it (path_watch_t) which enumerates every item of interest in the directory.
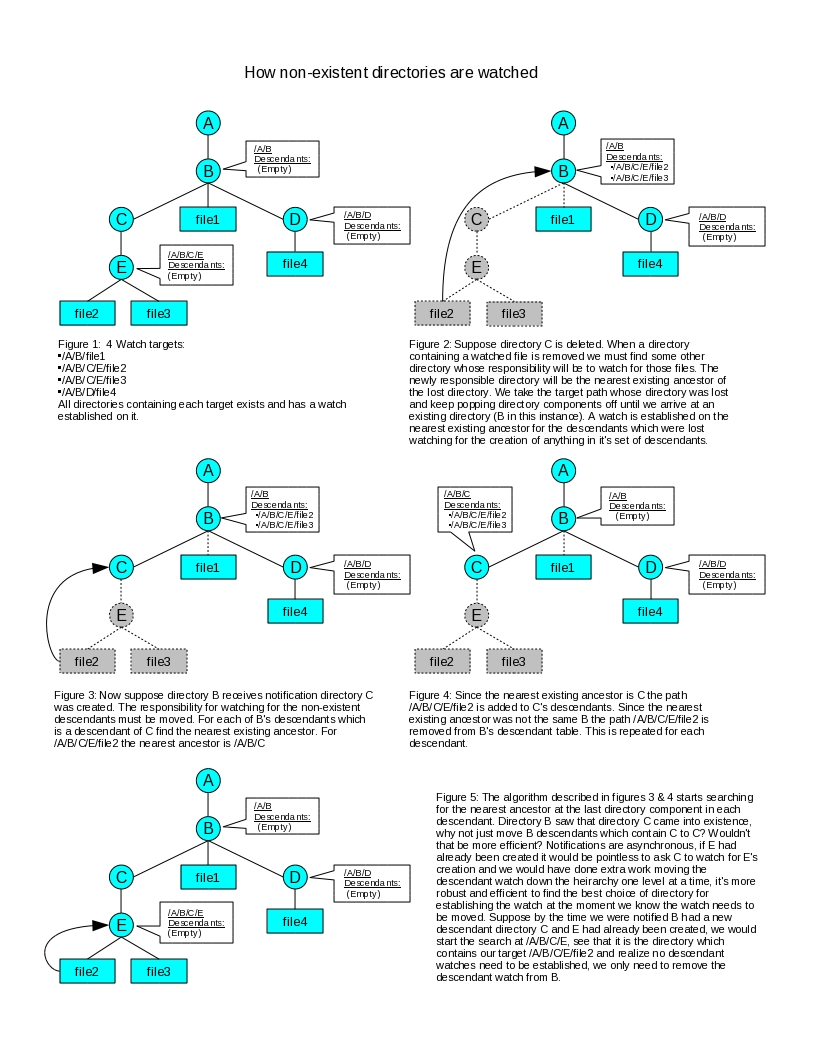
If we are asked to watch a file in a directory which does not exist we are confronted with the problem there is nothing to set an Inotify watch on. So instead we start at the directory closest to the file in the chain of directories comprising the file path and start walking up that chain toward the root until we find a directory which does exist. We call this the closest existing ancestor of the target. This is our best option for establishing a watch for the file. We inform that directory it needs to watch for the creation of a sub-directory which might lead to the file. This will be a descendant of the directory being watched. Thus a directory which has an Inotify watch on it must watch for any files it contains which are of interest and any sub-directory which leads to a descendant. Directories which have Inotify watches established on them are called watch points. Technically files contained in the directory are also descendants of the directory if one considers a path name as a sequence of path components. Thus anything a directory is watching we call a descendant watch.
If a descendant watch is for a non-existent directory and a sub-directory which might lead to the descendant watch is created in the directory then that directory is no longer the closest existing ancestor, the new sub-directory or one of it's descendants will now be the closest existing ancestor. Thus we must move the watch to the closest existing ancestor anytime directories are created or destroyed which lie along the path to the target. This makes the set of watch points ephemeral and fluid. If a directory has a descendant watch removed from it because it is no longer the closest existing ancestor it might not have anything to watch for anymore unless there are other descendant watches for it to track. So after removing a descendant watch from a watch point we check to see if it's set of descendant watches is now empty, if so we completly remove the watch point from Inotify observation. In a similar fashion a watch point might come into existence for no other reason besides the fact at the moment it's the closest existing ancestor for a watch.